How to use Neo4j to Monitor Customer Fraud in a Fintech App


We had a problem. In a fintech project that has products for both B2B and B2C markets, there appeared some less than honest users who were trying to game the system via multiple accounts.

It became clear that these users were connected in one of two ways—via either the same IP address or the same payment card number. As the product and marketplace continued to grow, the data amassed in three distinct SQL tables—one for user names, one for IP addresses, and yet another for payment cards.
Eventually, detecting malicious actors and preventing fraud became mired in queries upon queries, requiring more and more time and resources to weed out. We needed a better solution, both for our sanity as developers and for the continued safe growth of the products.
Enter Neo4j, a relational graph database that excels at exactly this type of problem. The accompanying programming language—Cypher—is designed to make it easy and efficient to write and execute queries in large datasets.
It all started with seven bridges
In 1736, Leonard Euler formulated and proposed a solution to what is now a classic problem in graph theory. In essence, the goal was to cross all seven city bridges in Königsberg without crossing any one bridge twice.
This guy was a busy and prolific mathematician, publishing over 500 books and papers throughout his life. At first, he thought the problem was trivial. But it seemed to gnaw at his curious mind. It took over 21 paragraphs in his mathematical to come to the following conclusion:

And so, graph theory was born. Read more about Euler and the seven bridges here.
At its most basic, a graph is an abstract mathematical object representing a set of vertices (points or nodes) and edges (lines) that connect them. For example:
Now, we can see graphs in use all around us. On metro maps and in the digital spiderwebs of social networks. In the digital product world, graph databases have a wide variety of applications.
Two of the biggest social networks clearly illustrate the differences between directional and non-directional graph structures. Facebook’s ‘friend’ connection is an ‘edge’ that connects two people only after they both acknowledge their connection.
In the Twitter social graph, however, relationships can be in one direction—Bob follows Alice—or bi-directional—Bob follows Alice and Alice follows Bob. We'll talk a bit more about directions later.
Main Components of Neo4j
In a database built on graphs, there is no such thing as a table with strictly defined fields. Rather, it operates with a flexible structure made up of vertices and edges with their own models with fields.
The three main components are:
- Vertex / Node: The essence of a graph DB. These can contain any number of properties in the form of key-value pairs and can also be labeled to define different roles.
- Edge / Relationship: Connects the nodes and always have a direction*, a type, a starting node, and a final node. Like nodes, relationships can also have properties.
- *Directions are not so important in this case but can be modified by using different labels depending on the demands of the graph.
- Label: These are used as a conditional node or edge type. Labels are case-sensitive and Cypher does not give any errors if you type the wrong name.
Writing with Cypher
Cypher is the programming language used for writing queries not only for graph database Neo4j, but also for MySQL. So if, like us, you run up against the limits of efficiency as your MySQL database grows in size and/or complexity, you’ll quickly be able to understand query construction in Neo4j.
Let’s walk through a simple example before we take a crack at that problem of querying users.
Fetch all the vertices:
MATCH (n) RETURN n
Creating a vertex with a Movie label and title property:
 Creating a connection between two vertices:
Creating a connection between two vertices:

Adding new properties to the top:

Deleting all vertices and edges:

Now let’s graph out those customers
To detect and prevent fraudulent activity on our platform, we need to quickly connect different users who are using the same IP address or payment card. And at any given time be able to see all these links for any selected user.
For this example, we will show how to connect users with the IP address as the criterion in our Neo4j graph database. So each node will be a user and each edge will be formed between them based on them having the same IP address.
For the user, we will use the following fields:
name: string
id ips: array
All the nodes will be labeled Person. For edges, we only store an array of IPs, because in some cases the users have more than one identical address. These edges are marked with the IP label.
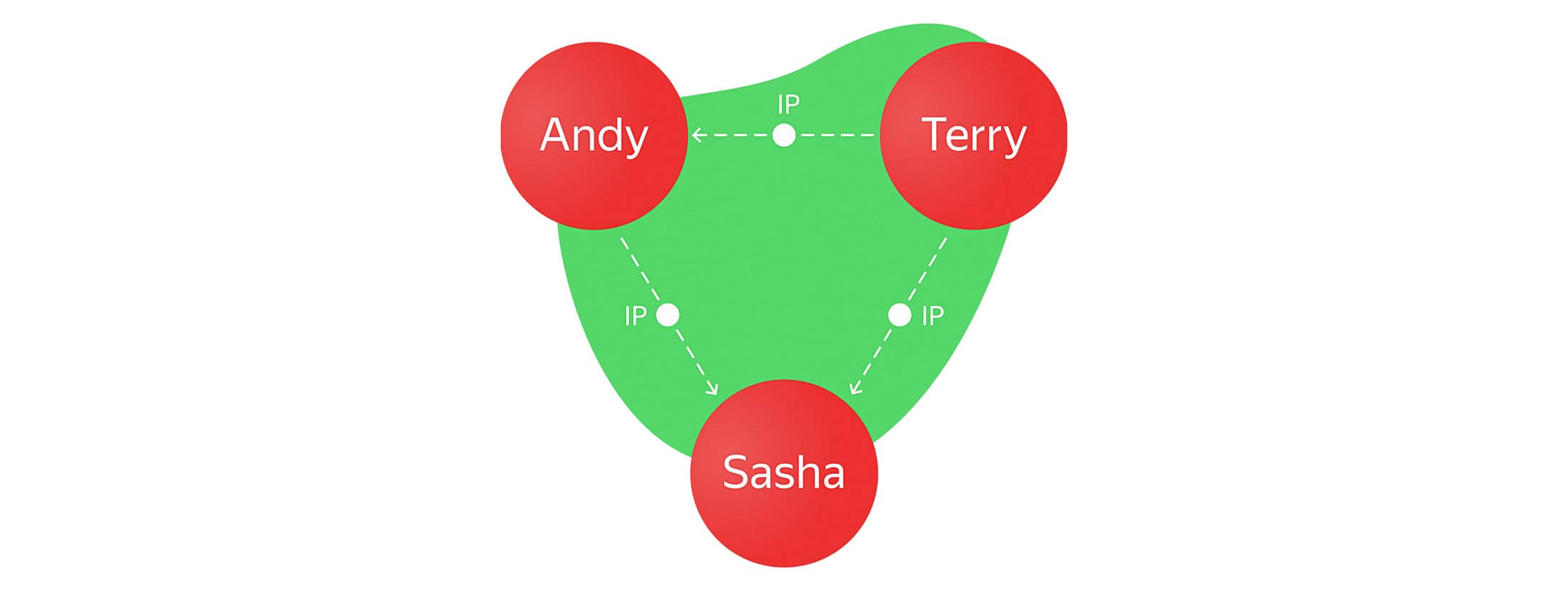
So, let’s make a small three person graph to start:

Now we can MATCH (n) RETURN n to see our graph:
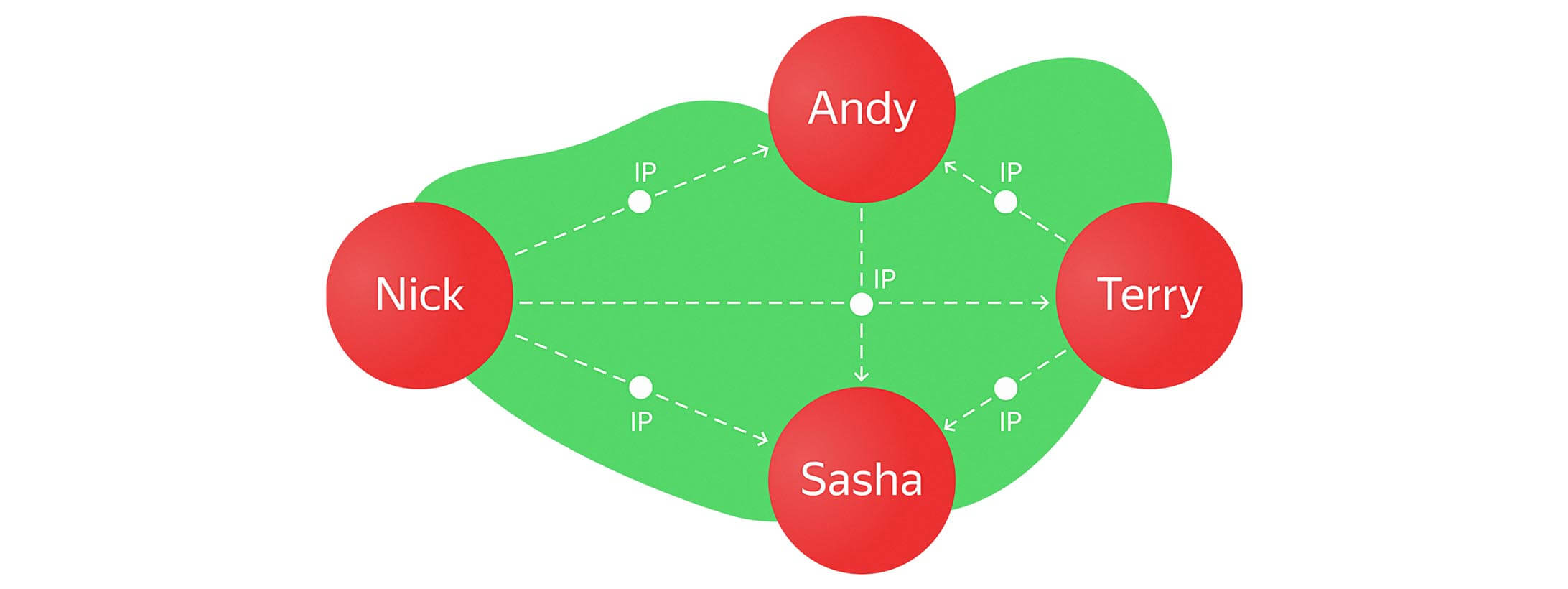
All good so far, now we’re going to add a new user. So we have to create their node and find out if they are using the same IP address as anyone already in the database. If they are, then we want to create a labeled edge between them.

Note that we want to exclude the new user so that we don’t make a loop edge back to themselves. And so our graph continues to grow:
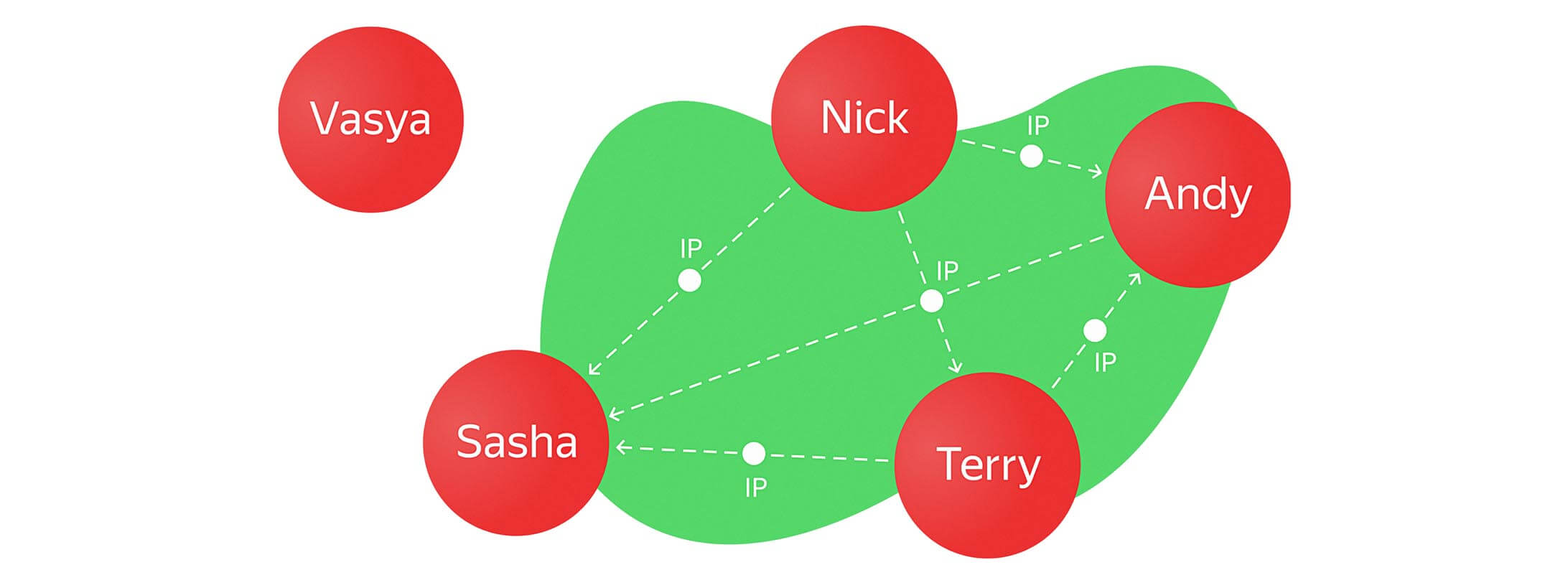
Now, we need to start throwing some new IP addresses into the graph. So let’s add another user with a different address:

And now we have Vasya sitting all alone:
Now we can see what happens if Andy adds another IP address to his array that is the same as our lonely user Vasya.

The point of this is to add a new IP address to Andy’s array and simultaneously search for other users with that new address AND create a new edge between them based on that new IP. And so we get:
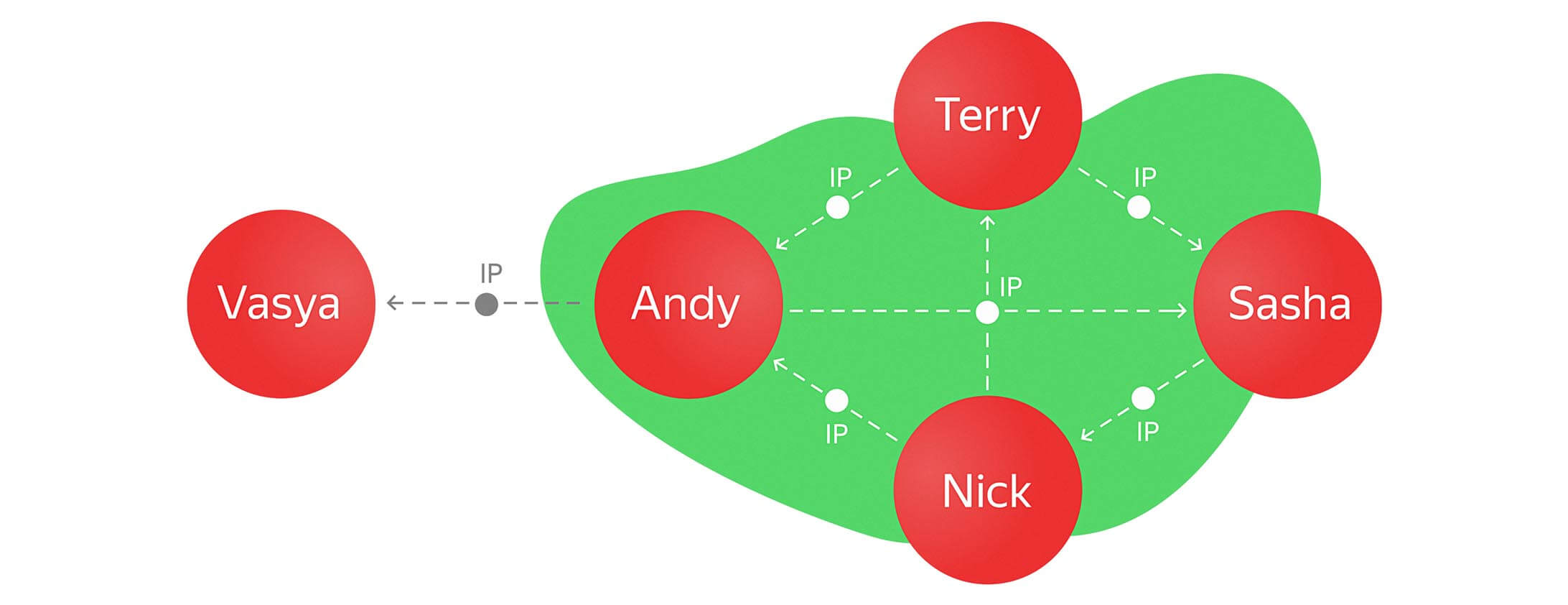
Andy turns out to be a bit of a nomad, so each time he logs in from a new IP address, we can update it AND search for new connections based on that new address:

At this point, no one else is using the same IP address, so no new edges are formed. But let’s say that Vasya decides to follow Andy:

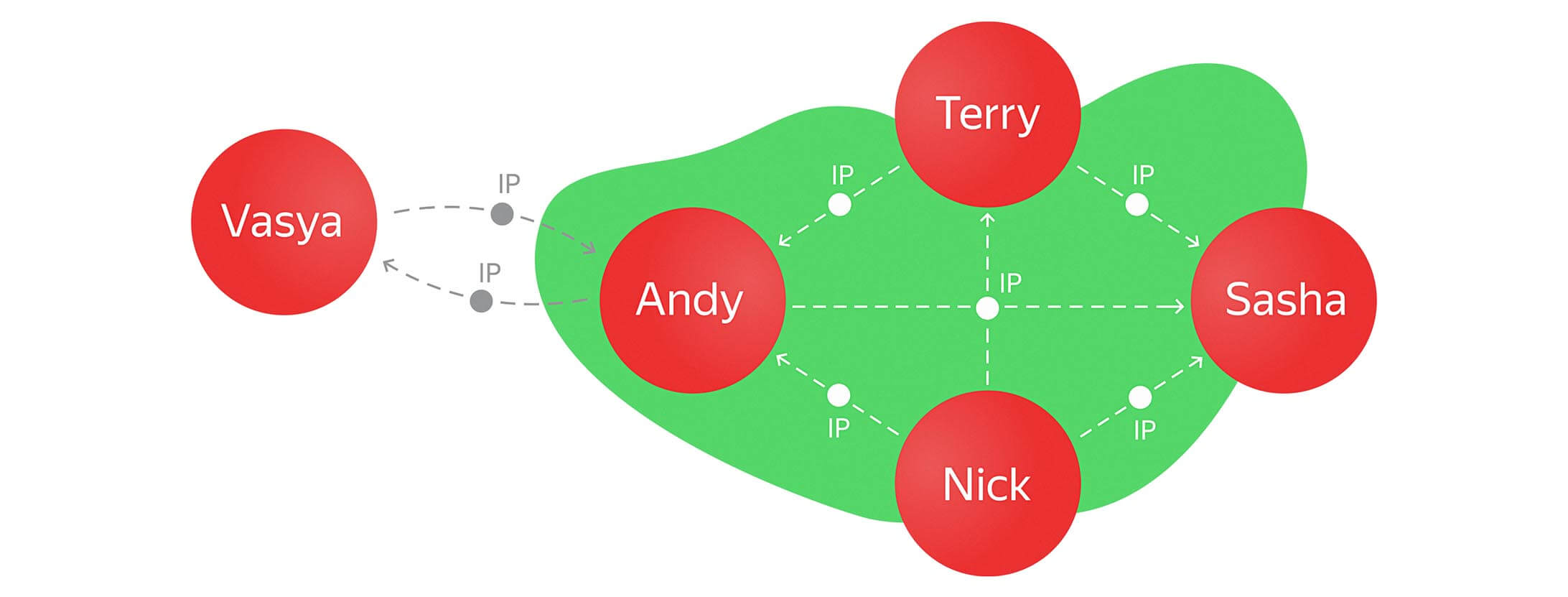
This creates an unnecessary edge. Remember, each edge is an array of IP addresses so there is no need for this.
MATCH ()-[r]-() WHERE ID(r)=35 DELETE r
Without getting too deep into all the permutations that can grow out of this graph structure, the goal is to create a clear system of connections as the user base grows (more nodes) and the IP addresses also increase (edges).
So the algorithm looks like this for each user and new IP address:
- We add a user with an IP address OR add a new IP to an existing user
- We search for all users who have the same address
- Within those users, we are looking for those who already have a connection with the user.
- Update this connection by adding the new IP address to the array.
- We also search for users with the same address who do not have a connection with this user yet.
- And we create this new edge between them with the IP address in the array.
To see this code in action, let’s add one final user:

And now, the moment of truth:

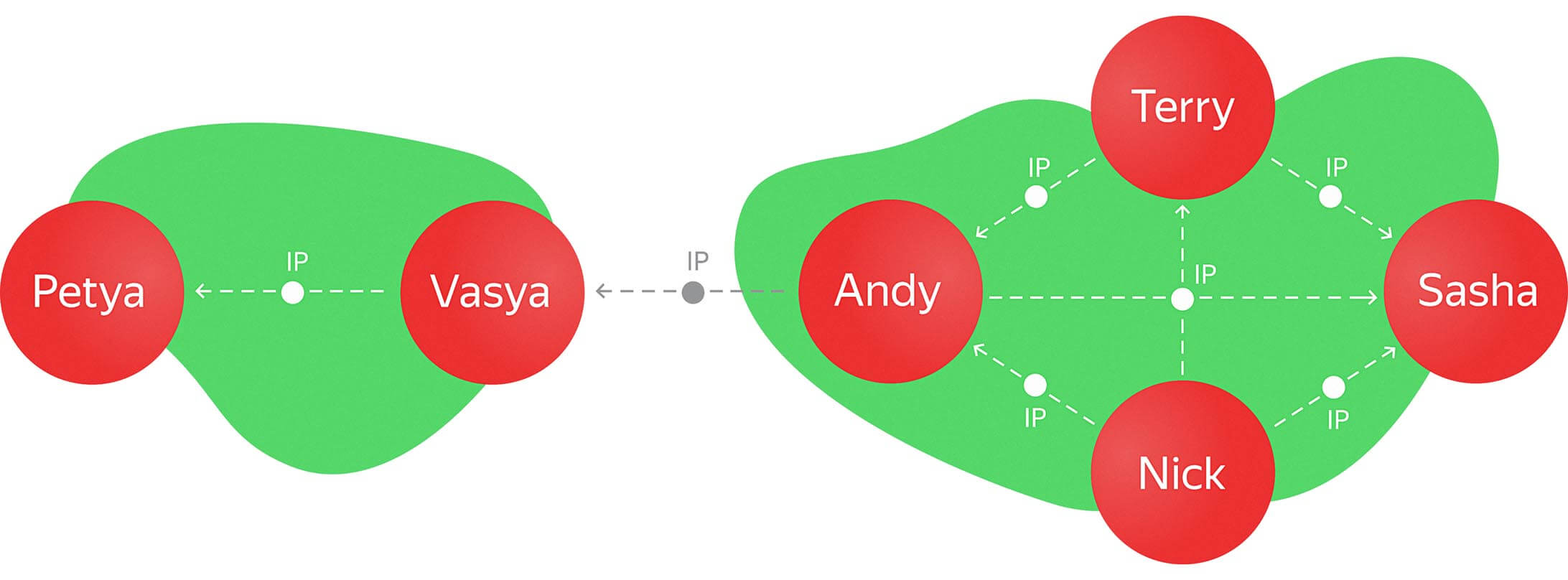
So what can you do with this?
Back to finding solutions to our problem of fraudulent users. In a database of thousands, you can easily write queries to see if there are any connections between users. If we suspect two users of acting together on the platform, we can:

And we can look at the results in a table:

Beyond Online Banking
As we’ve shown, Neo4j is a sensible and efficient database option for categorizing, connecting and querying a customer base of any size. By using the same Cypher language as MySQL, it’s a short learning curve for experienced developers to make the transition to Neo4j.
Fraud prevention and protection are a core priority of all digital banking products. There is no more rapid way to dissolve your customer’s trust in a product than exposing their bank accounts to malicious actors.
But Neo4j graph databases can be applied across a range of digital industries, especially ones that rely on relationships between customers. For any product that has a social aspect—whether it is sharing ideas or music or photos or work opportunities—Neo4j has proven capable of efficient performance at scale.
From our early years of working with MongoDB and Robomongo to the latest trends in decentralized databases, our teams always work towards matching an ideal DB to the goals of the product.
Coming up soon, we’ll add a dedicated page to Paralect.com outlining the technology stack and approach we use specifically for fintech projects. Sign up below to keep up with our latest news.



