Natural Language Processing for a Fistful of Dollars

With the help of technology and a pinch of magic, we define intent for each message. But the miracle is how we train the model that defines intent and understands context. Machine Learning tech is rapidly changing the way your clients solve their problems — and it’s getting cheaper too!

Natural Language Processing is all the rage these days. With OpenAI’s imminent release of the GTP3 API, machine learning and NLP could very rapidly shift towards being much more affordable to every level of startup.
So, we want to take a moment to clarify how we got to this point and what this means for product founders who want to integrate NLP and ML in their current or future apps. Spoiler — it’s easier, more performant and more accessible than ever!
Outline
- Historical Overview
- GoogleAI’s BERT Explained
- Amazon Comprehend
- Amazon Lex
- Using AWS in Your Product
History of NLP
Natural Language Processing — aka NLP — lies at the intersection of linguistics, computer science and machine learning. NLP solves the problems of interaction between machines and people through our native human languages.
The story of NLP begins with Alan Turing's “Computing Machinery and Intelligence”. In this article, he asked “Can machines think?” But the terms ‘machine ’and‘ think’ are too vague, too ambiguous to give an accurate answer. So Turing suggested answering an alternative question — “Can a digital machine win a simulation game?”
Programmers have tackled this question many different ways over the years, but their solutions have broadly fallen into two different approaches:
- ‘Rule-based’ — where all the rules for parsing and text processing are created manually by the programmer, which helps to achieve high accuracy and process anomalies in the text. But this approach greatly complicates the architecture of the program.
- ‘Machine learning’ — allows for probabilistic analysis, but requires a voluminous body of texts for training.
The most accurate and optimal solutions include both approaches at the same time.
GoogleAI, BERT, and the Evolution of Neural Networks
The latest trend in NLP algorithms is Google AI Language Bidirectional Encoder Representations from Transformers aka BERT. It presents state-of-the-art results in a wide variety of NLP tasks, including Question Answering (SQuAD v1.1) and Natural Language Inference (MNLI).
But first things first. Let's start with Recurrent Neural Networks.
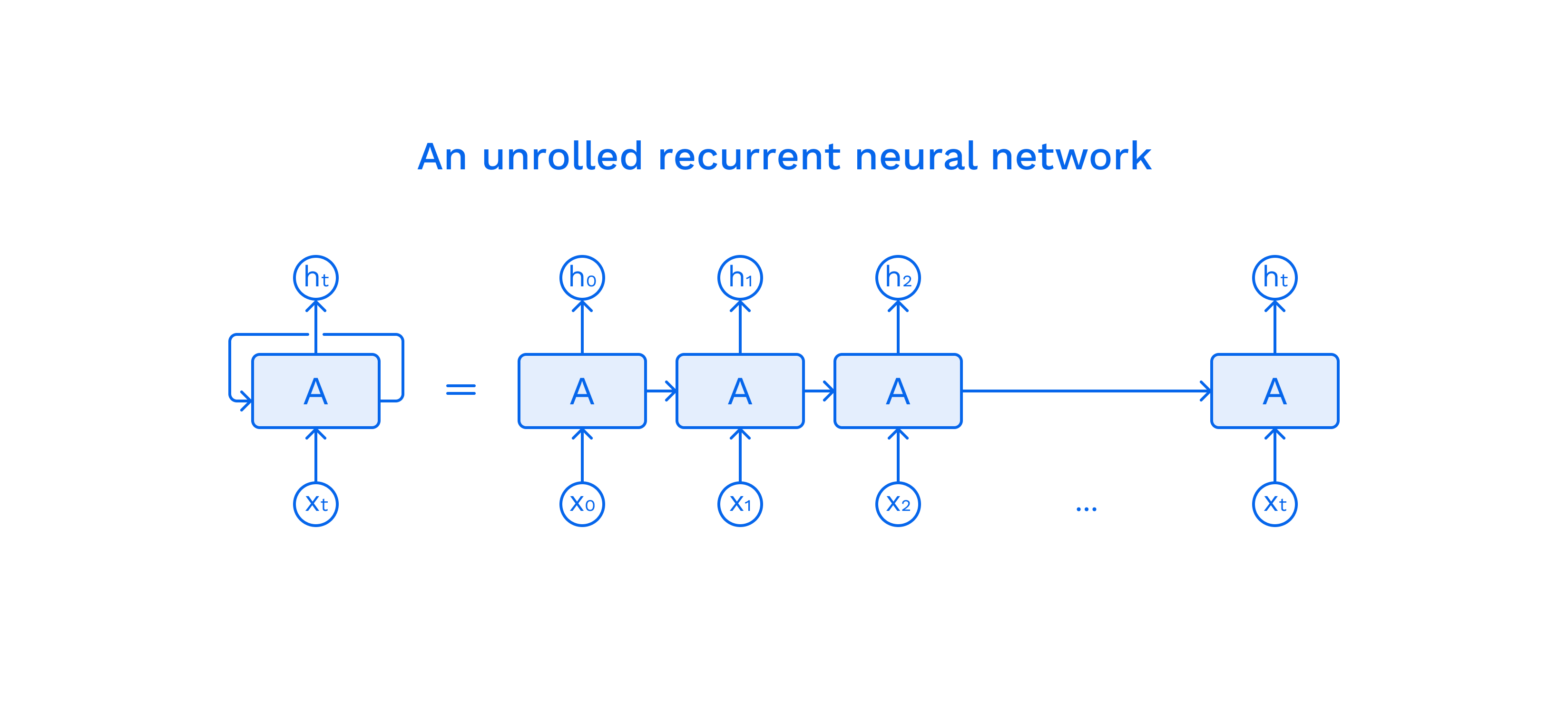
Because each neuron has an internal state, this model can process any sequence.
The main advantage of this model is that it can process sequences and — in a certain sense — take into account the context of a value in a sequence. The main drawback of this model is the so-called Gradient vanishing and exploding problem. With a sufficiently long sequence, the gradient of the function “disappears”.
Simply put, the longer the sequence, the less context is taken into account. In 1991, some smart guys found the way to reduce the impact of this problem — they proposed adding an additional element to each cell called Long Short Term Memory (LSTM).
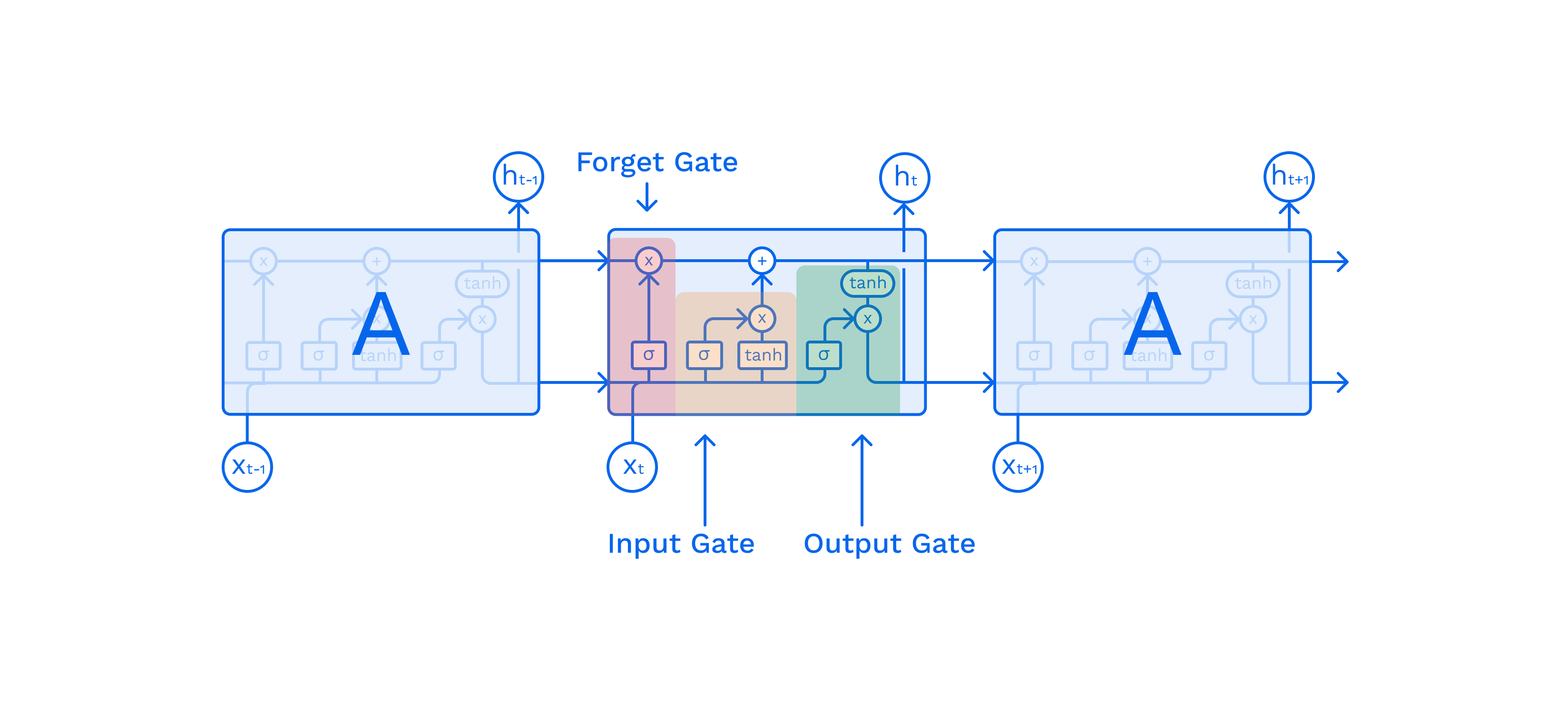
The additional memory cell allows us to keep the gradient (context) in memory for longer, but this is not a complete solution to the problem. The length of the processed sequences has increased by no more than one order — from 100 to 1000. In a nutshell, we get additional layers — the Input, Output and Forget Gates — which help preserve the gradient of the function.
In 2017, a new generation of a recursive model was introduced — the Transformer.
BERT uses the Transformer network to solve the sequence transduction or neural machine translation. These are any tasks of converting one sequence to another — for example, converting audio information into text (speech recognition).
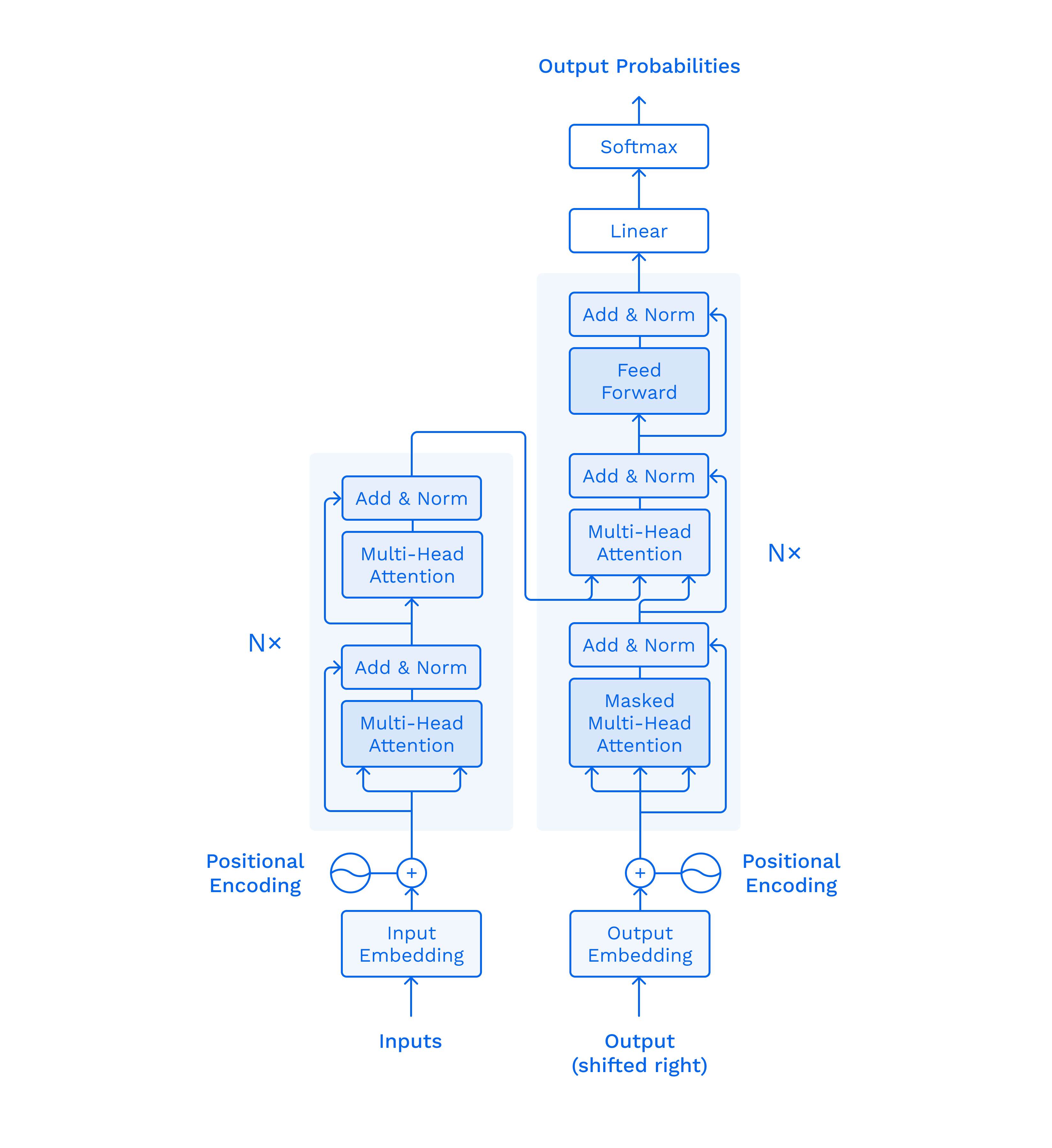
Fundamentally, the architecture repeats the idea of a RNN, but let's take a closer look at what exactly happens there. As an example, we will use the translation from English to French:
The big red dog -> Le gros chien rouge
It consists of 2 parts — encoder (left) & decoder (right).
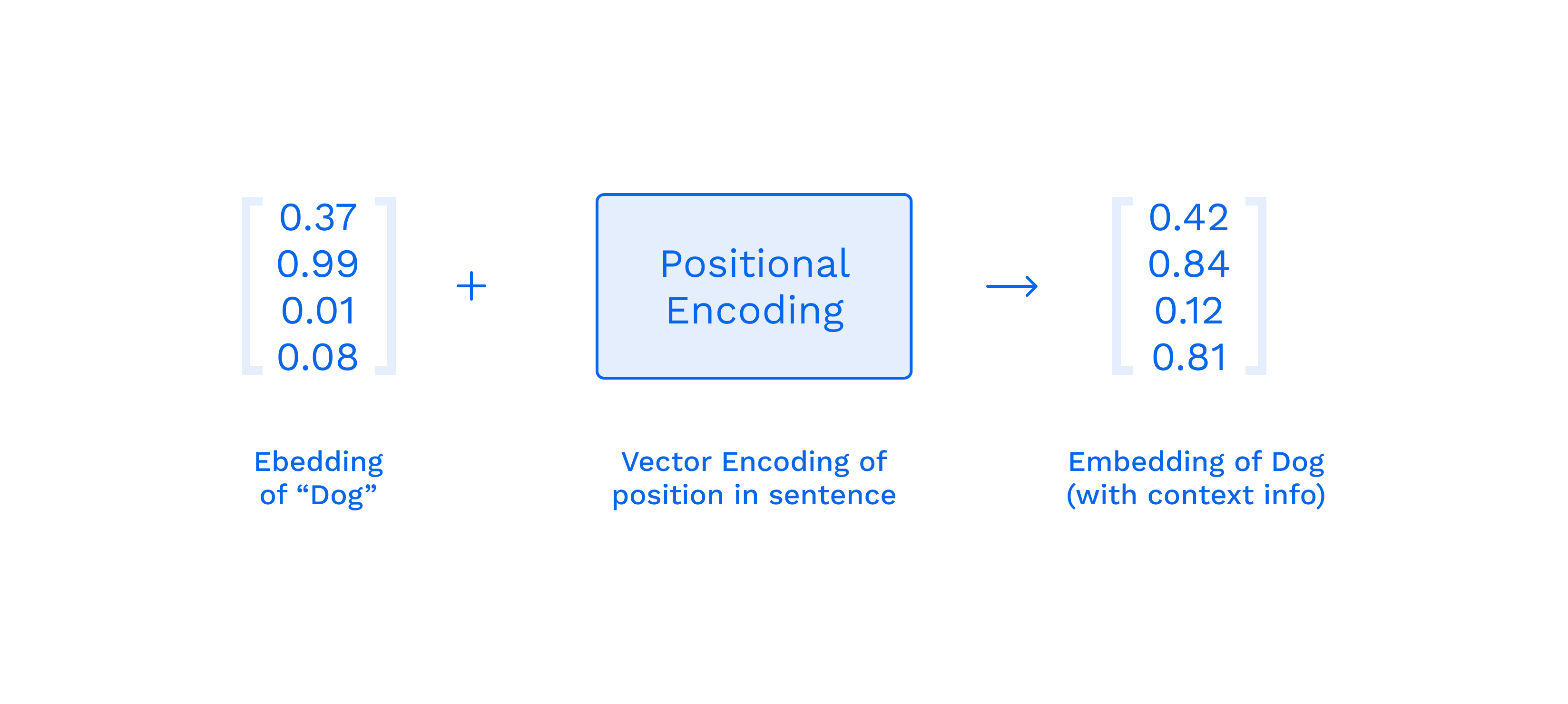
Input Embedding and Output Embedding “display” the words at the entrance to the embedded space. Each word has its own coordinates and in this space, we can determine how close these words are by value by determining the distance between them.
Input Embedding receives the Nth word of the original sentence “big”, and Output Embedding N-1 receives the word of the translated sentence “Le”. After that, we only operate with vectors. Positional Encoding generates a vector that provides a context based on the position of the word in the sentence.
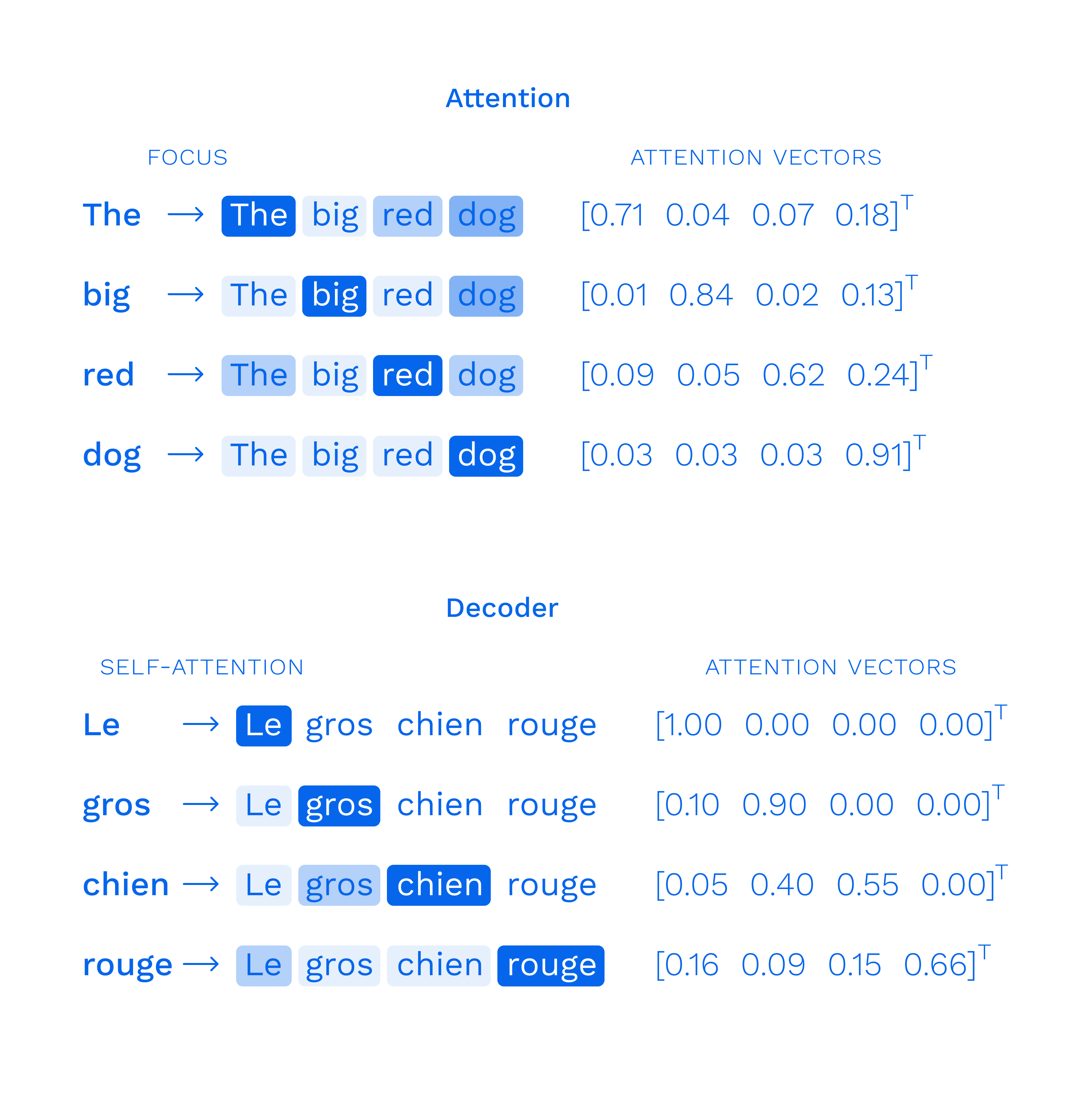
But understanding the position of each word is not sufficient. Even in such a simple sentence, the words have different levels of importance.
Enter Multi-Head Attention. The main task of this block is to indicate the relationship of the current word with the rest of the words in the sentence. A vector of meanings is generated for each word — that’s why it’s called multi-head.
This block is located in the encoder and compares the meanings of words received in the encoder & decoder. In other words, it encapsulates Language-to-Language interaction.
Other Elements of the Transformer:
- Masked Multi-Head Attention: this network is present only in the encoder, it is necessary to mask values that we have not yet calculated.
- Feed Forward: applies attention vector to previous values and prepares data for the next decoder/encoder block.
- Add & Norm: normalizes the data.
- Linear: compares the values of a vector and a word — the reverse action of Embedding.
- Softmax: calculates the probability distribution gives the most probable outcome.
So in the end, we have the Transformer:
Now that we understand what transformers are, it will be easier to understand the “breakthrough" the engineers at Google made.
Earlier, the analysis of a text was carried out in a definite direction. Now, the analysis is bidirectional — or rather non-directional since the sentence is analyzed in its entirety.
So the BERT model allows Google’s search to understand queries better than the people who make them.
Amazon Comprehend
Amazon Comprehend is a natural language processing service that extracts key phrases, places, names, brands, events, and sentiment from unstructured text. It’s powered by sophisticated deep learning models trained by AWS. It does not use the direct meaning of the words, but their meaning in context. This eliminates the majority of failures in determining the topic.
Amazon Comprehend's main advantage is extensibility. If your business provides services in a very specific domain, you can easily expand the model with Custom Entities and Custom Classification. Custom Entities allow you to find terms/words or as serious people say — “any sequence of symbols” that you need.
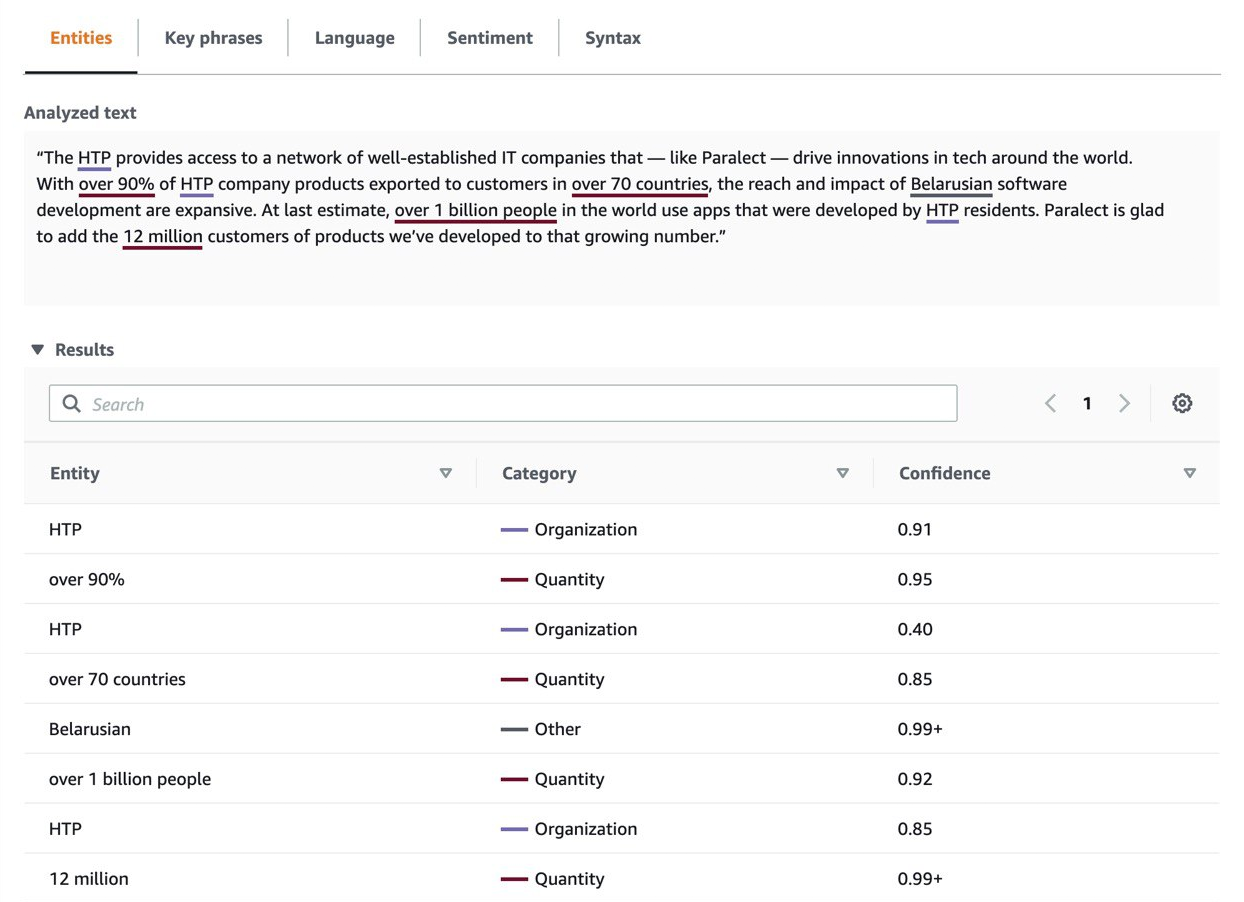
For example, it solves the tasks of sorting and distributing mail, articles, customer feedback, and any information in natural language. Obviously, the more data you provide, the more accurately Comprehend will find it. Topic Modeling allows you to train models only from the content of these documents.
Custom classification allows you to categorize sets of documents. You can classify emails with customer feedback, send positive reviews to the Department Head, draw conclusions based on negative ones and automatically “mark them as read”.
Amazon uses Latent Dirichlet Allocation (LDA) — a generative probabilistic model for collections of discrete data based on the Bayesian theorem. For example, most ‘normal’ people will conclude that if a text contains “undifferentiated heavy lifting,” then this is most likely an article about sports. But if the text contains the names Bayes or Dirichlet, it’s probably about serious ML.
If that makes your head spin, don’t worry!
To integrate Comprehend in your product, you do not need to understand the “elementary transformations” of Bayes' theorem.
You don’t even need developers with deep expertise in ML. Rather than “undifferentiated heavy lifting”, you can focus on features and quick delivery.
Amazon’s interface and documentation allow us to build products based on Machine Learning technologies with the help of a team of web developers and a week of research.
Amazon Lex
While Comprehend is for text, Amazon Lex delivers deep functionality and flexibility of natural language understanding (NLU) and automatic speech recognition (ASR). AWS provides not only an API, but also a GUI. You just need to pass the sample phrases and the more data you use, the more accurate the classification will be.
This service makes it possible to create voice and text conversation bots. The core elements of Amazon Lex are the Intent, Slot and Channel types. With just these three entities, you can create a homemade Alexa (well, almost).
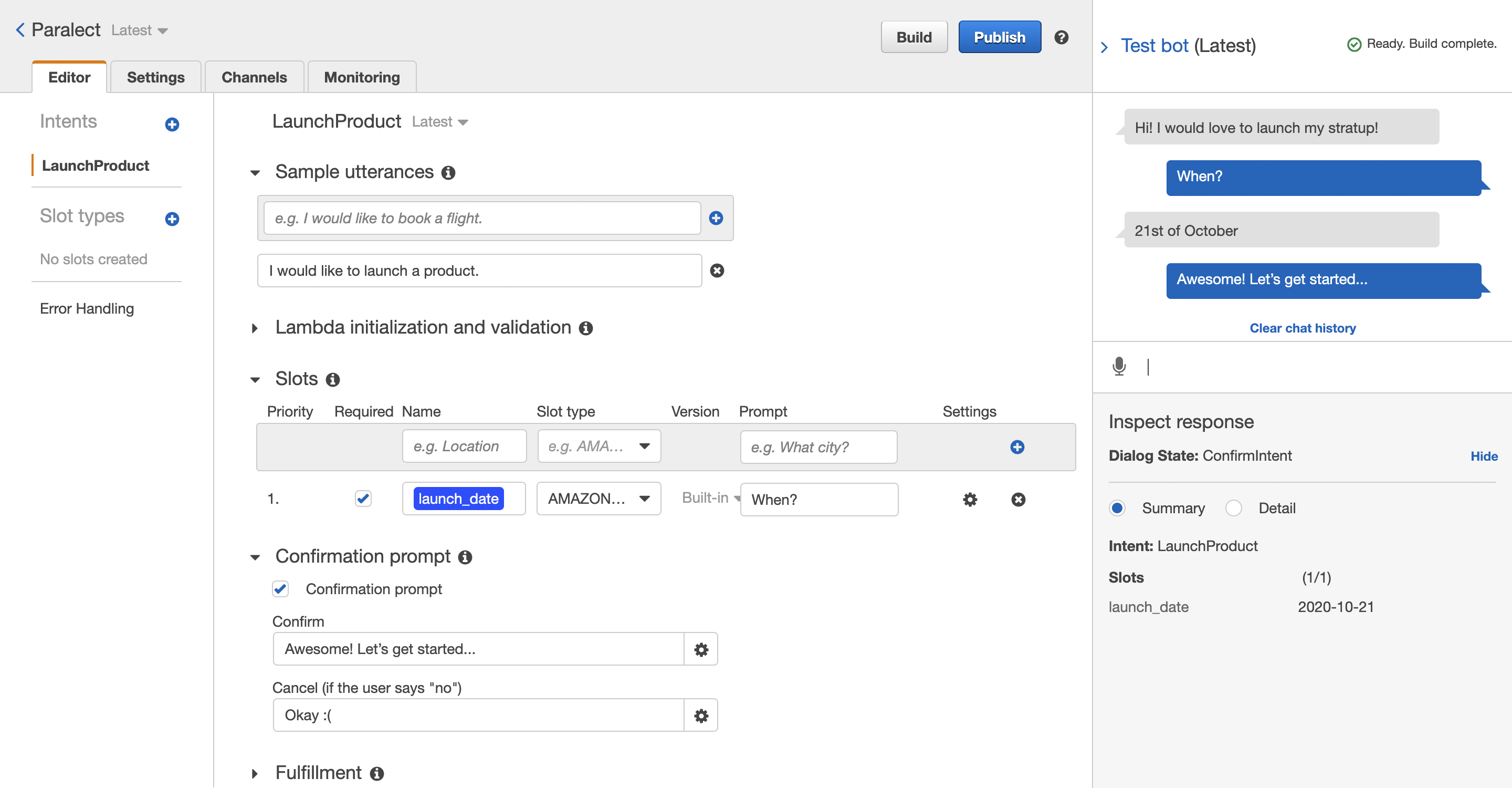
Of course, the most relevant data is the history of communication with your customers. Lex allows you to handle errors, set clarification prompts and a hang-up phrase to communicate more nicely with your clients.
For each Intent, you can specify a set of Slots. A Slot is the data that the client must provide in order to fulfill the intent. If you are selling pizza, the user must specify the size and toppings, otherwise they will not be able to order it. For each Slot, you can specify a specific prompt.
This adds interactivity to your application and we can finally rid the world of static multi-step forms.
Setting the Channel type allows you to adapt the behavior for each channel. For example, to be more concise when chatting on Twillio, Lex can use slang short forms such as LOL, IDK, JFYI. But on Facebook, it can switch to full forms of words.
Last but not least — business logic. AWS Lex allows you to use hooks in the AWS Lambda functions format. This immediately and significantly increases your ability to customize and validate behavior! You can automate not only communication with the client but also part of your business.
NLP and Your Product
Thus, Machine Learning has been democratized by services like AWS Lex and Comprehend.
What’s that mean for entrepreneurs? With financial thresholds to deep learning tech falling, both the quality of ML services and the quantity of successful products integrating ML is on the rise.
Now, to change the world, you don’t need rich parents and a Harvard degree — middle-class parents are more than enough!
At Paralect, we focus on product delivery and time to market using cutting-edge technology. Services such as AWS Lex and Comprehend — combined with a no-code approach — allow you to launch, expand or iterate apps quickly and within a sane budget.
But as they say, a picture is worth a thousand words, so visit our Showroom to see what we’ve already achieved with our partners or contact our sales team directly — [email protected]!



