Why to Use Risk-Based Testing in Product Development

Risk, and the mitigation of risk, is a central part of our lives. At work, at home, while traveling — we tend to mentally prepare for something to invariably go wrong. A delayed plane, lost baggage, sick colleagues, traffic jams, and, of course, bugs in production!

As a tech product company, risk mitigation is simply intrinsic to our MVP development and iteration process. In this post, we'll explore risk-based testing as we've come to implement it. And we'll look at one product where unforeseen risks forced us to step back and improve our risk-based testing strategy.
Defining 'Risk' in Product Development
Let's start with a working definition. Risk is an existing or emerging factor of a process that has a possible negative impact on the process. More simply, risk is something that can happen and can lead to a bad outcome. Of course, we want to avoid this in our products.
But first, it's important to recognize the difference between a risk and a problem. A risk is a problem not yet manifested. And the opposite is also true — a problem is a risk that has manifested itself. Therefore the main aim of risk-based testing is to quash problems while they are still only risks, and thus preventing the end user from ever seeing them manifest as a problem.
To mitigate risk is to understand exactly where vulnerabilities in the system are and how they could affect the product as a whole. Once we clearly separate risks from problems, the goal of risk management becomes simpler and more understandable.
For example, let’s say your team uses one testing environment for developers and one for QA testers. This is often a source of problems down the line, rather than a risk. Another example of a problem is simply an unstable build that does not pass the simplest smoke testing.
Origins of Risk-Based Testing
In 1994, James Bach began writing and speaking about a risk-based testing management approach. This is one of the first references to the fact that you can test software based on the risks that are encountered when implementing it.
In his article The Challenge of "Good Enough" Software Bach mentions that if we minimize or eliminate all problems that may be related to the quality of our product, then by default the quality of this product will be high.
In 1996, Ronald P. Higuera and Yacov Y. Haimes published the article Software Risk Management, where the risk management methodologies for software are described. This marked the starting point for the Risk-Based Testing approach — within three years James Bach published Heuristic Risk-based Software Testing.
On to the Theory
Software testing strategies are selected depending on the specific goals of the project. In projects with complex business logic, testing is based on stringent requirements in the system design.
One type of requirements-based strategy is risk-based testing. Logically, the parts of the system functionality that are most exposed to risks are tested first.
Two Types of Risk
- Product Risk: These can be either caused by internal or external factors.
- An example of an internal risk is the rapid growth and complexity of a product’s functionality, which increases the likelihood of defects in stable parts of the system. A clear test base and automated testing can go far in mitigating these types of risks.
- External risks include the factors that we cannot influence — dependence on external systems and their possible failure during operation. But we can plan activities that will reduce their impact on our system. As a precaution; use backups, handle exceptional cases, display warnings for users.
- Project Risk: This includes risks such as...
- Incomplete assessment of labor costs for project development and testing.
- A testing plan that is not tied to the project plan.
- The dismissal or illness of key employees
- Generally the risk of ignoring risks.
A regular review and audit schedule with clear communications with the QA team can help avoid most project risks. The key thing to remember is that most project-level risks can be mitigated through joint efforts of the testing, development and project management teams.
Sometimes we can do nothing with a risk or our risk testing strategy is not sufficient enough to completely mitigate it. It happens. In this case, the best decision is to insure your project against the repercussions. Write down clear instructions for responsive action. Maybe it never happens, but it’s better to be prepared.
How to work with risks?
The risk management strategy for testing consists of 4 stages:
- Risk Identification - the team compiles a list of all possible risks.
- Risk Assessment - the list of risks is analyzed and classified by priority.
- Risk Mitigation - to determine how thoroughly we will test the risks and work with them - what tests need to be done and how much time to devote to testing.
- Risk Management - work on eliminating risks, risk analysis, identification of new risks.
This may go without saying, but at the early stages it is essential to include risk-based testing time in the project roadmap. Testers have to be allocated to the task and time needs to be set aside to analyze the results. And, of course, the more clearly this is documented at each stage, the more lessons you can carry on to the next project!
Risks need to be identified and assessed by a group of stakeholders during brainstorming sessions. This will be most effective with a full team, which should include a business analyst and/or a carrier of knowledge about the system from the customer, developers, product manager and project manager, and the QA team.
You can be creative working with risks — write out possible risks in tables/lists/matrices, prioritize them and assign severity, and compile risk catalogs of those that have occurred or may occur. Going further, you can use one of the technical methods of risk assessment and management - FMEA (Failure Mode and Effect Analysis).
Failure Mode and Effect Analysis
FMEA is the most popular risk-based testing approach. It is a model for analyzing the causes and consequences of system failures by identifying potential defects and their causes. In FMEA, the project team is trying to identify all the components, processes, and modules in which a failure can occur.
This failure can lead to a deterioration in the quality of the software. Three indicators are used to measure such failures: severity, priority, and likeliness. A Risk Priority Number (RPN) is assigned for each risk and, depending on the indicators, the testing depth is laid.
For example — an online casino management project where we allow three main functions: deposits, bonus management, and player management.
During a brainstorming session, the project team identifies several main risks of the system:
- incorrect calculation of the bonus under the given conditions for users.
- the user’s funds are not credited to their account in the online casino.
- the system does not withstand the simultaneous load of 300+ users creating deposits.
- incorrect saving of user data during authorization.
Next, we need to determine the value of indicators for each risk. For example, on a scale of 1-5 where 1 is very serious/high probability and 5 is not serious/low probability.
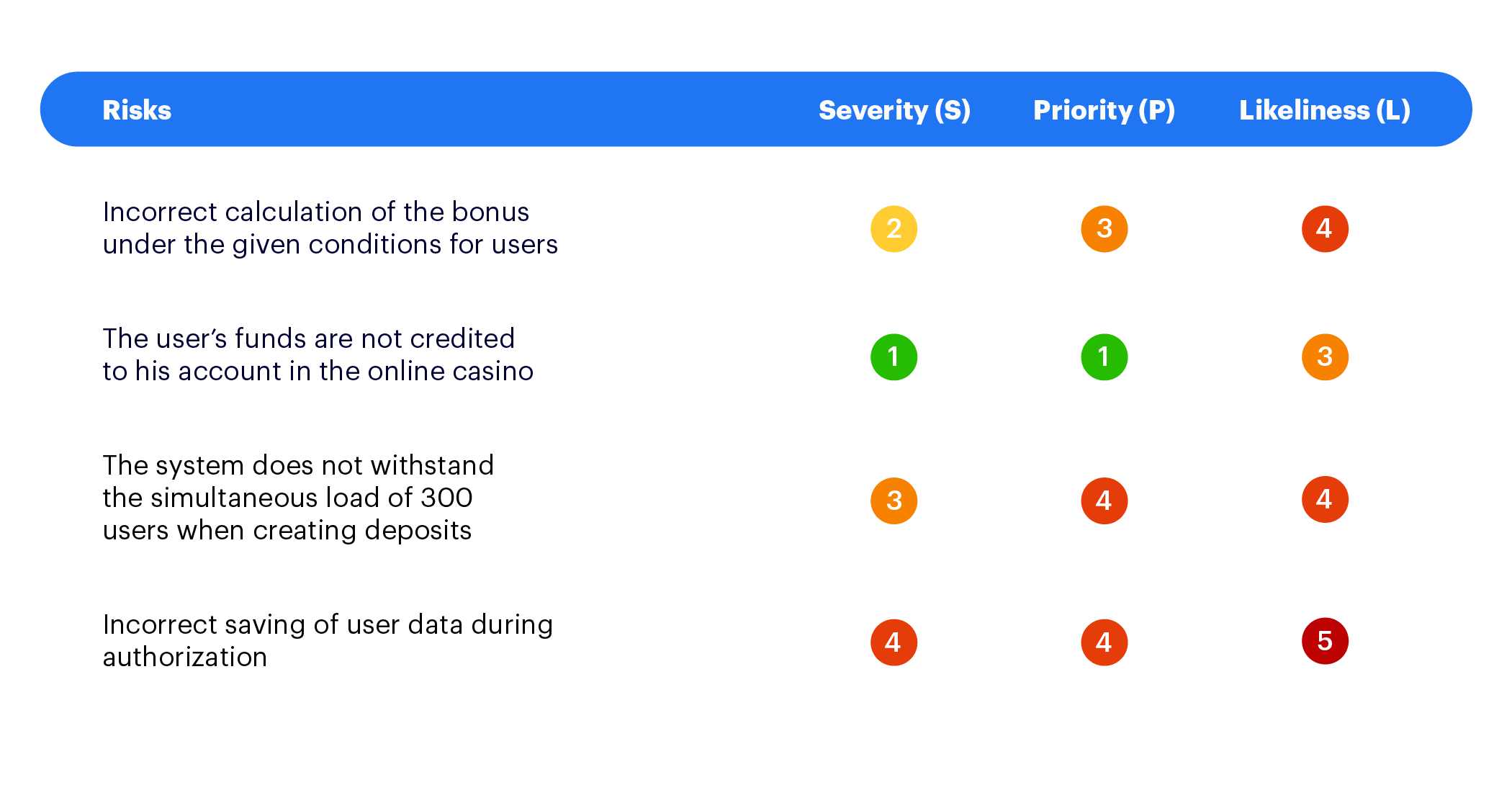
After the analysis, the Risk Priority Number indicator is calculated using this formula RPN = S x P x L. As a result we get the following calculation of risk prioritization.

Now, depending on the RPN indicator, the testing depth is outlined:
- If the RPN value is 1-10, then we perform a full test with all sorts of positive and negative checks, including minor tests.
- If the value of RPN is 11-30, then we perform mandatory positive testing and basic negative checks of the basic functionality.
- If the value of RPN is 31-70, then we perform a surface test of functionality.
- If the RPN is over 70, then we perform testing for this risk only if there is free time.
The advantages of the FMEA model are that it uses a transparent model for assessing testing volumes based on the risks in using the software. One downside is the formality of this approach, which can be solved by adapting this method according to your own project needs.
Our Problem and How Risk Testing Helped
So, after all the theoretical introductions, we can go to the most interesting topic of this article — a real-world example of how a risk-based strategy helped us recover from near disaster.
Let's start from the very beginning.
Our project was initially developed as an intermediary in the payment system between a bank and an online casino. Later, the project pivoted and our client introduced new requirements and functionalities. Therefore the main functionality was shifted to work with a new type of transaction — transfers between traditional currencies and cryptocurrencies.
We successfully implemented several integrations with payment processors, developed a scoring system to determine a “good” or “bad” transaction and possible fraud, and designed the process of gathering transaction statistics, etc.
We had been actively working with our main customer for about 1.5 years. During this time we modernized the system to the requirements of his business. There were a lot of interesting tasks, not only in terms of implementing various features, but also in the process plan.
We, as a whole team, thought out solutions and strategies to meet the challenges of tight deadlines and important requirements that needed to be processed as soon as possible.
And so no one noticed the storm brewing.
While we were excitedly adapting the project to new requirements under the pressure of looming deadlines, important aspects of risk management had been pushed to the side. For example, a thorough analysis of new business requirements, development of technical solutions, even full regression.
Of course, it could not continue, and this whole powder keg full of our cuts in mitigation work mixed with tight deadlines exploded.
A few days after the next production release and within a 48 hour period:
- Transactions seriously broke down. From the beginning, we did not devote enough time to studying all the details in the API documentation and did not take into account several “temporary” responses that could come from the payment processor. So we had not tested them sufficiently in a test environment.
- Problems arose with processing the transaction hashes.
- Then, as a bonus after quickly fixing those issues, all the users’ personal data was accidentally updated at once. This disrupted the casino player scoring system and the user account levels.
The situation was critical — both for the customer, the end users, and for us. It required a very thorough analysis of all the reasons why and where things went wrong. This is exactly what we did right after we returned the production to the correct state and carried out all stabilization work. Afterwards, we realized that risk-based testing could be a partial salvation for us.
Better Late than Never
Therefore, we started assessing the risks that had already caused problems and went through all the stages from the very beginning.
At the first stage, Risk Identification, we made a list which we continued to add to further. This list included those disruptions that already happened, and those that fortunately did not happen, but which we saw as risks going forward.
Then began the analysis of all these risks and their classification by priority — Risk Assessment. The result was a table with product and project risks, which also indicates the probability and severity (on a 1-5 scale where 1 is very serious/high probability, and 5 is minimal seriousness/low probability):
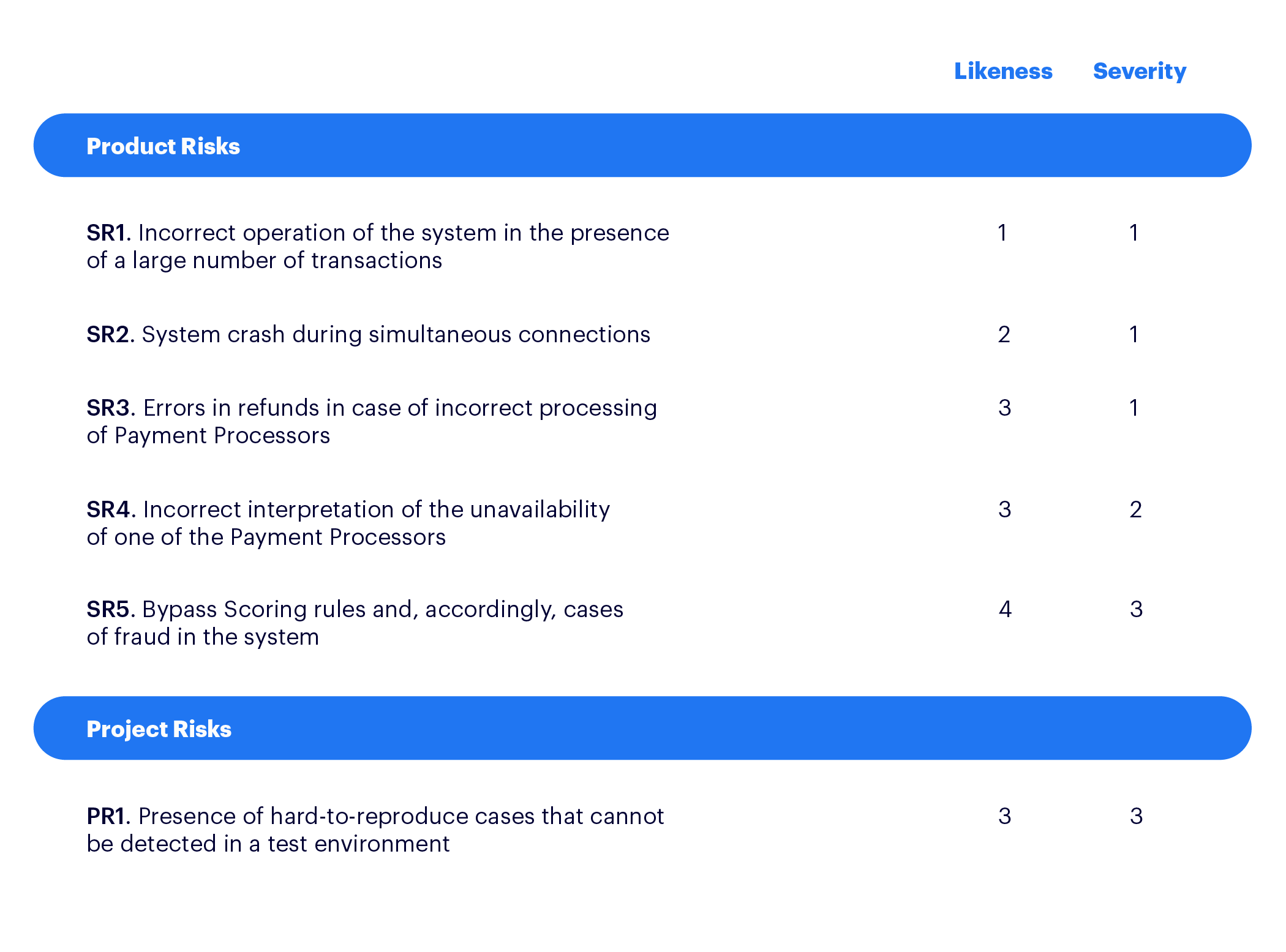
In the next stage — Risk Mitigation — we needed to determine the depth of risk testing, so all the existing test cases were reviewed and the missing scripts were added. For some risks, only a possible response action plan was drawn up.
As a result, the following checks were selected, which correlated with each risk:
- TC1. Check the load if there are more than 10 simultaneous connections and transactions.
- TC2. Load verification with 5 simultaneous connections and transactions
- TC3. Check functions such as search, column filter, sorting and pagination on the Transaction Listing page if there are more than 800,000 transactions;
- TC4. Check functions such as search, column filter, sorting and pagination on the Transaction Listing page in the presence of 400,000 transactions;
- TC5. Simulation of temporary inaccessibility of payment processors;
- TC6. Processing of all statuses from payment processors;
- TC7. Checking the scoring for completed transactions.
We intentionally did not use the FMEA method, since in our situation everything was quite clear in terms of priorities and testing depth. Instead, we assigned a different color to each risk, which was related to the severity of the risk and the depth of testing.
So we ended up with a table that showed the correspondence of all risks and checks:

The risks highlighted in red and yellow required thorough stress testing and analysis of the capabilities of the system. In any case, a red risk is a high priority, yellow risks are less likely, but checks on them are also mandatory.
Risks highlighted in green required running all the positive scenarios and the main negative checks. In addition, we identified project risk actions — additional activities and solutions that can help.
With risk “PR1: The presence of hard-to-reproduce cases that cannot be detected in a test environment,” we took the following steps:
- Prepare “pre-production” which is as close as possible to the real application environment, in conjunction with all external systems.
- Write end-to-end test scripts that pass through all the adjacent systems and provide transaction verification.
Conclusion and Findings
We can say with confidence that risk-based testing can help cover the most risky areas with test cases. Such a strategy is ideal for a system with complex business logic — most fintech products for example. The costs of any error can be very high and expensive, a risk-based approach provides additional insurance.
The main thing is that this insurance is timely!
We as a team walked away from this experience well aware that adhering to a risk-based testing strategy earlier in the product life cycle could have saved us from many headaches. The lessons from this have carried over into how we approach testing across all our projects.


